Cloud Data Platform Consulting
Starkes Fundament
Starkes Business

bereits auf unsere Expertise:










Skalierbare Datenplattformen, die Potenziale entfalten
Im Zeitalter rasanter Marktveränderungen entscheidet die Kraft deiner Daten darüber, wie erfolgreich dein Unternehmen agiert. Wir entwickeln mit dir eine Cloud Data Platform, die mit deinen Anforderungen wächst, technologische Trends aufnimmt und deine Daten optimal nutzbar macht – von Anfang an oder als gezielte Weiterentwicklung deiner bestehenden Datenarchitektur.
Mit uns schöpfst du den vollen Wert aus jedem Byte und stellst sicher, dass deine Infrastruktur morgen stärker ist als heute. Unser Anspruch: Wir gestalten Lösungen, die nicht nur mit dem Markt Schritt halten, sondern dir echten Vorsprung verschaffen – passgenau, robust und nachhaltig. So wird jede Datenbasis zum Wachstumsmotor deines Business.
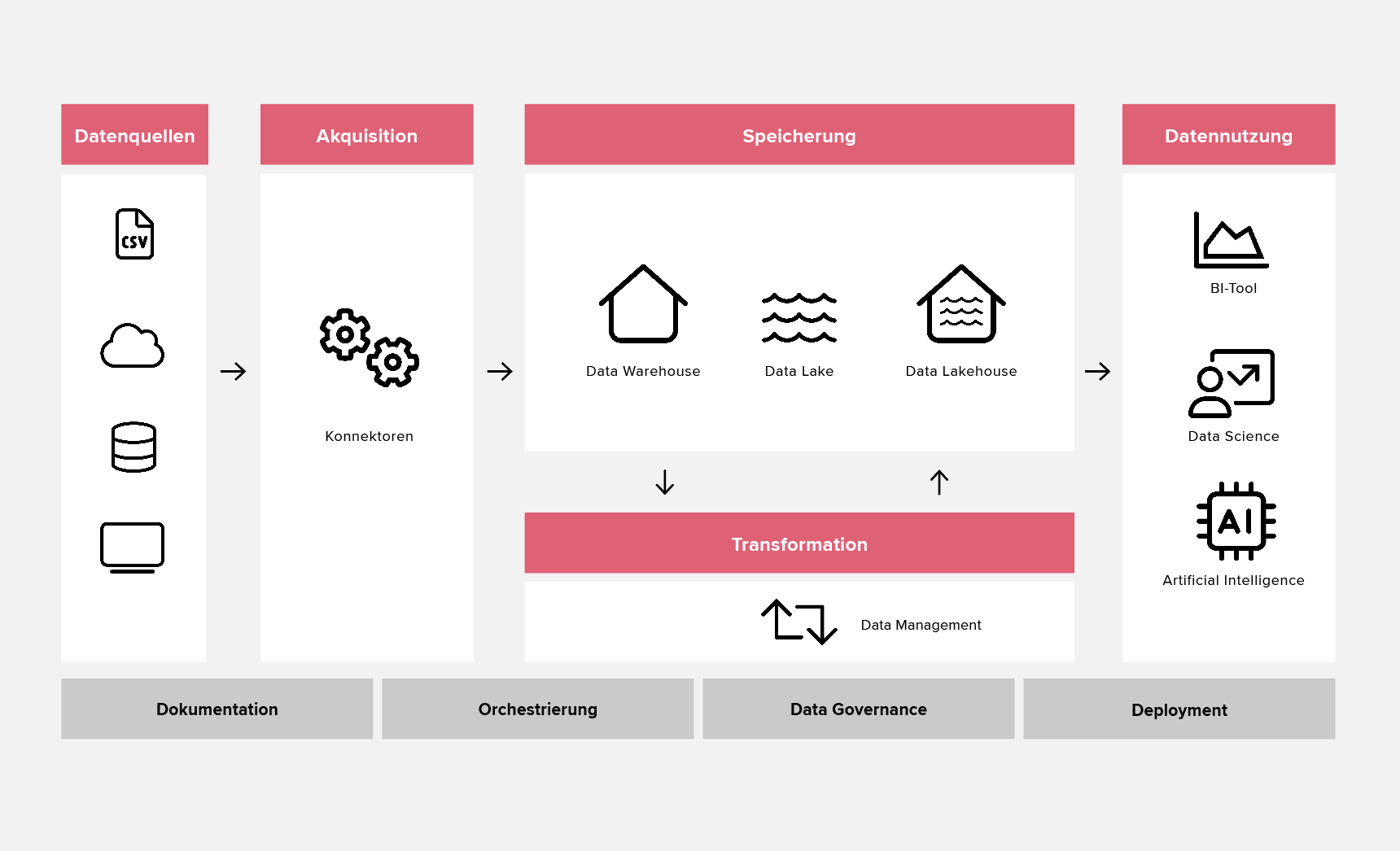
Unsere Cloud Data Platform Services
Data Discovery & Assessment
In fokussierten Workshops analysieren wir deine gesamte Datenlandschaft und decken versteckte Potenziale auf.
Infrastruktur-Assessment
Wir analysieren Cloud-Ressourcen, Pipelines und Betriebsprozesse auf Effizienz, Sicherheit und Skalierbarkeit. Als Ergebnis stehen konkrete Handlungsempfehlungen mit transparentem Business-Impact.
Data Architecture Alignment
Wir entwerfen eine skalierbare Datenarchitektur, die sich an der Unternehmensstrategie orientiert und als Grundlage für deine Datenplattform dient.
Data Integration
Wir verbinden heterogene Quellen und sorgen ein einheitliches Datenmodell. Egal ob monatlich, täglich oder in Near-Realtime: Wir liefern verlässliche Daten für Reporting und AI-Anwendungen und bauen Datensilos ab.
Data Pipeline Development
Wir automatisieren den End-to-End-Datenfluss mit robuster Orchestrierung und testen jede Transformation. Das Ergebnis: Zuverlässige Datenbereitstellung, wenig Wartungsaufwand.
Datenmodellierung
Wir modellieren deine Daten entlang der Geschäftsprozesse nach bewährten Standards und schaffen eine robuste Grundlage für Reporting, Self-Service und Automatisierung.
Infrastruktur-Automatisierung
Wir automatisieren das Ausrollen der Infrastruktur, um Set-ups reproduzierbar, effizient und fehlerfrei bereitzustellen.
Performanceoptimierung
Wir analysieren Performance-Bottlenecks und optimieren technische Stellschrauben – für schnellere Abfragen und geringere Betriebskosten.
Entwicklungsstandardisierung
Wir etablieren Entwicklungsstandards, um nachhaltige, wartbare und skalierbare Lösungen zu schaffen.
Data Quality
Durch automatisierte Data-Tests und Anomalie-Erkennung stellen wir sicher, dass deine Datenbasis stets fehlerfrei, konsistent und geschäftskritisch nutzbar bleibt.
Data Governance
Wir entwickeln ein Governance-Framework, das Compliance, Nachvollziehbarkeit und Sicherheit entlang deiner gesamten Datenwertschöpfungskette sicherstellt.
Security
Wir härten deine Datenplattform nach Security-Best-Practices. Sowohl technisch als auch organisatorisch. Für Daten, die sicher sind und es bleiben.
Schulungen & Coaching
Ob in unser Databricks oder Fabric Schulung oder im individuellen Coaching. Wir befähigen dein Team, Pipelines zu warten und weiterzuentwickeln. Das senkt Abhängigkeiten von externen Dienstleistern und verbessert die langfristige Wartbarkeit deiner Datenplattform.
Was deine Data Platform leisten muss – und wie wir das möglich machen.
.svg)
Durch den Aufbau der Plattform sind wir nun in der Lage, datengetriebene Entscheidungen zu treffen und unsere Produkte kundenzentriert weiterzuentwickeln.

HD+
Durch die geschickte Verknüpfung von Daten haben wir nicht nur unsere internen Prozesse optimiert, sondern Datensilos aufgebrochen und uns dadurch einen entscheidenden Vorteil im Wettbewerb gesichert.
Aachener Grundvermögen
Wir erweitern mit Advanced Analytics nicht nur die emotionale Kundenbindung, sondern steigern zudem die positive Customer Experience
Aktuell nutzen rund 150 Vertriebsangestellte sowie das Management aus drei Ländern das entstandene automatisierten Vertriebs-Controlling.
Die Marketing-Ausgaben sind eine unserer relevantesten Budget-Posten. […] Eine skalierbare, robuste und nachvollziehbare Data Pipeline spart signifikante Kosten.

Finde den passenden Service für dich
Data Platform
Nicht das passende Paket für dich dabei?
Schreib uns einfach eine Nachricht und in einem Erstgespräch finden wir gemeinsam heraus, wie wir dir weiterhelfen können.
Die führenden Technologien
bei uns im Einsatz






Wie wir arbeiten – und was du davon hast
Wir helfen dir, dein Reporting zu automatisieren und deine Datenprozesse effizienter zu machen – mit Erfahrung, Hands-on-Mentalität und einem klaren Plan.
Bevor wir loslegen, wollen wir verstehen: dein Setup, deine Ziele, deine Realität. Erst dann gehen wir in die Entwicklung.
Wir entscheiden nicht für Tools – sondern für Lösungen. Wir beraten unabhängig und empfehlen nur, was für dich wirklich Sinn ergibt.
Wir sprechen verständlich – auch bei komplexen technischen Themen.
Wir setzen KI da ein, wo sie sinnvoll ist. So können wir schneller und effizienter Ergebnisse erzielen.
FAQs
Ein klassisches Data Warehouse ist ein zentraler Speicher für Daten. Eine Cloud Data Platform geht darüber hinaus und verbindet Datenmodelle, Infrastruktur-Automatisierung, Governance, Pipelines, DataOps und Analytics in einer integrierten Umgebung, was ideal für Reporting, Self-Service-BI und Advanced Analytics ist.
Ein klassisches Data Warehouse stößt an Grenzen, wenn Datenvolumen wachsen, neue Datenquellen hinzukommen oder Analytics- und KI-Use-Cases entstehen. Dann braucht es eine flexible Dateninfrastruktur, die sich skalieren lässt, verschiedene Datentypen unterstützt und automatisiert betrieben werden kann.
Skalierbare Dateninfrastruktur sorgt dafür, dass dein System mit wachsendem Datenvolumen und durch neue Use-Cases nicht zusammenbricht. Sie ermöglicht stabile Datenbereitstellung, schnelle Analysen, geringere Betriebskosten und bessere Integrationen in BI oder ML-Tools.
Wir sind technologieoffen und arbeiten mit gängigen Tools und Cloud-Plattformen wie Snowflake, Databricks, Microsoft Fabric, Azure und dbt. Welche Tools am besten passen, hängt von deinem Use-Case und deiner bestehenden Umgebung ab.
Cloud-Infrastruktur ermöglicht elastische Rechenleistung, hohe Performance und schnelle Bereitstellung neuer Umgebungen. Dadurch lassen sich Analytics-, BI- und KI-Use-Cases effizient umsetzen und bei Bedarf skalieren.
Hast du noch offene Fragen?
Lass uns deine Fragen bei einem unverbindlichen Erstgespräch klären.
Mehr zum Thema Data Warehouse

Cloud Migration
Mit gezielter Planung, modularen Ansätzen und KI-Unterstützung zu nachhaltigem Wachstum und Innovation.

Byte auf Byte
Eröffne deine Möglichkeiten, denn davon hast du viele. Als Inspirationsquelle empfehlen wir dir deine Daten und unsere data!.

Modern Data
Optimiere mit einem modernen Tech Stack deine Dateninfrastruktur.

